如何将namenode与SecondaryNameNode分开配置
本文共 2075 字,大约阅读时间需要 6 分钟。
转自:http://www.aboutyun.com/thread-8146-1-1.html| 问题导读 1.如何将namenode与SecondaryNameNode分开? 2.SecondaryNameNode单独配置,需要修改那些配置文件? 3.masters文件的作用是什么? 我们这里假设你已经安装配置了hadoop2.2,至于如何配置可以参考,。 在这个基础上,我们对配置文件做一些修改: 1.增加masters文件 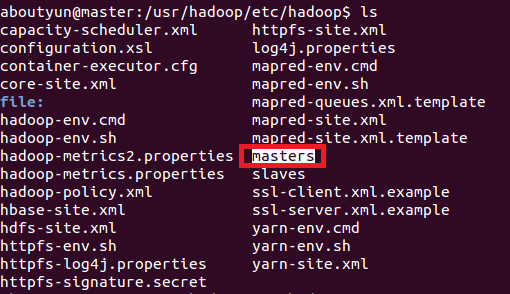 这里面放什么内容还是比较关键的,这里我们指定slave1节点上运行SecondaryNameNode。  2.修改hdfs-site.xml 在下面文件中增加如下内容:(记得下面亦可写成ip地址,这里为了理解方便,写的是hostname) 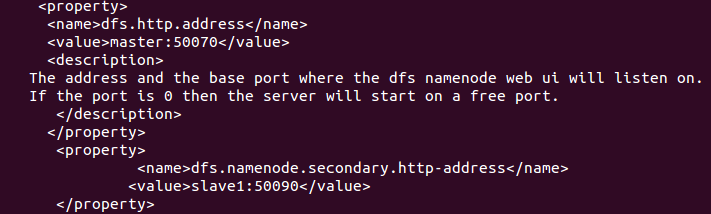 3.修改core-site.xml文件  上面修改完毕,相应的节点也做同样的修改 下面我们开始启动节点: 输出如下内容:  然后查看节点: (1)master节点:  (2)slave1节点  (3)slave2节点  停止节点: 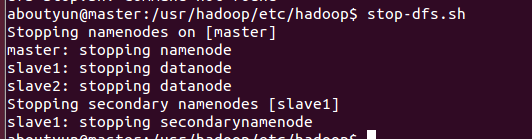 |
转载地址:http://rbyxi.baihongyu.com/
你可能感兴趣的文章
研华USB4711A采集卡高速中断模式采集总结
查看>>
从零起步CMFCToolBar用法详解
查看>>
CMFCRibbonStatusBar用法
查看>>
CMFCControlRendererInfo类的参数
查看>>
史上最详细MFC调用mapX5.02.26步骤(附地图测试GST文件)
查看>>
CMFCShellListCtrl使用方法
查看>>
mapnik的demo运行
查看>>
python支持下的mapnik安装
查看>>
milvus手册
查看>>
查看pytorch基于cuda 的哪个版本
查看>>
多目标跟踪的简单理解
查看>>
Near-Online Multi-target Tracking with Aggregated Local Flow Descriptor
查看>>
Joint Tracking and Segmentation of Multiple Targets
查看>>
Subgraph Decomposition for Multi-Target Tracking
查看>>
JOTS: Joint Online Tracking and Segmentation
查看>>
CDT: Cooperative Detection and Tracking for Tracing Multiple Objects in Video Sequences
查看>>
Improving Multi-frame Data Association with Sparse Representations for Robust Near-online Multi-ob
查看>>
Virtual Worlds as Proxy for Multi-Object Tracking Analysis
查看>>
Multi-view People Tracking via Hierarchical Trajectory Composition
查看>>
Online Multi-Object Tracking via Structural Constraint Event Aggregation
查看>>